Create an API endpoint for an ML model




When you deploy a model on Baseten, you can call it via an API endpoint with zero configuration. This saves you the effort of building and deploying a model server in Flask or Django, making it faster to interact with models.
But when working with generative AI models, there's often more complexity to working with model input and output. From streaming LLM responses to parsing base64-encoded Stable Diffusion output, it can take some glue code to integrate the model with your application.
In this post, we'll cover the API endpoint available for deployed models on Baseten and how to integrate it with your application. All you’ll need is an API key. You can call the API endpoints from the command line, your programming language of choice, or an API tool like Postman.
Calling ML model endpoints
Every model in your Baseten workspace is available behind an API endpoint. You can experiment with this endpoint directly from your model dashboard using the "Call model" button.

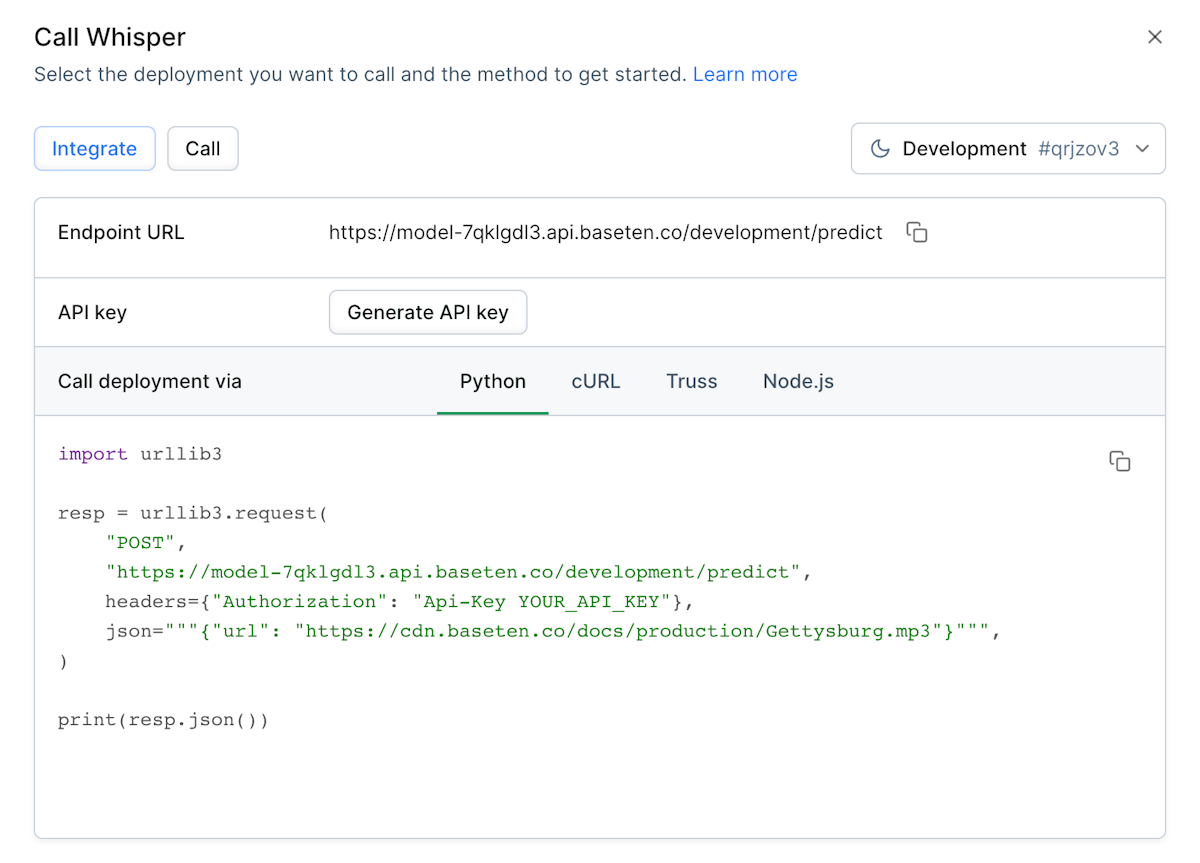
Here is an example model input for Whisper:
{
"url": "https://cdn.baseten.co/docs/production/Gettysburg.mp3"
}Which returns:
1{
2 "language": "english",
3 "segments": [
4 {
5 "start": 0,
6 "end": 6.5200000000000005,
7 "text": " Four score and seven years ago, our fathers brought forth upon this continent a new nation"
8 },
9 {
10 "start": 6.5200000000000005,
11 "end": 11,
12 "text": " conceived in liberty and dedicated to the proposition that all men are created equal."
13 }
14 ],
15 "text": " Four score and seven years ago, our fathers brought forth upon this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equal."
16}Integrating ML model endpoints
Of course, your ML model will need to be integrated into your application to parse model output and use it in production. The call model modal also provides instructions for calling your model with Python, cURL, JavaScript, and Truss.


For more on using API endpoints, see docs for model inference.
Subscribe to our newsletter
Stay up to date on model performance, GPUs, and more.











