Deployment and inference for open source text embedding models




TL;DR
A text embedding model transforms text into a vector of numbers that represents the text’s semantic meaning. There are a number of high-quality open source text embedding models for different use cases across search, recommendation, classification, and retrieval-augmented generation with LLMs.
Text embedding models aren’t flashy like large language models, but they’re a foundational piece of the natural language processing field and a key component for building production-ready applications on LLMs.
Why create text embeddings?
At face value, turning nice human-readable text into a long list of numbers might seem pointless. One text embedding can’t be used for much. But creating embeddings from a corpus of text—say every post on your blog or every paragraph in your documentation—enables use cases like:
Search: given a query, create an embedding of that query and compare its similarity with embeddings from the data set, and return the most relevant content.
Retrieval-augmented generation (RAG): use embedding search to grab chunks of content to use as context for text generation with LLMs.
Recommendations: surface related content like similar blog posts or podcast episodes.
Classification and clustering: categorize text by similarity.
As each of these use cases relies on creating a set of embeddings, it’s important to use the same embeddings model for both the initial dataset and any subsequent embeddings (such as search queries).
What is a text embedding?
A text embedding encodes a chunk of text as a vector (a list of floating-point numbers). This vector represents the text’s meaning in an n-dimensional space.
This is difficult to visualize at the scale of real text embedding models, which have hundreds of dimensions, but here’s a simple example in two dimensions:

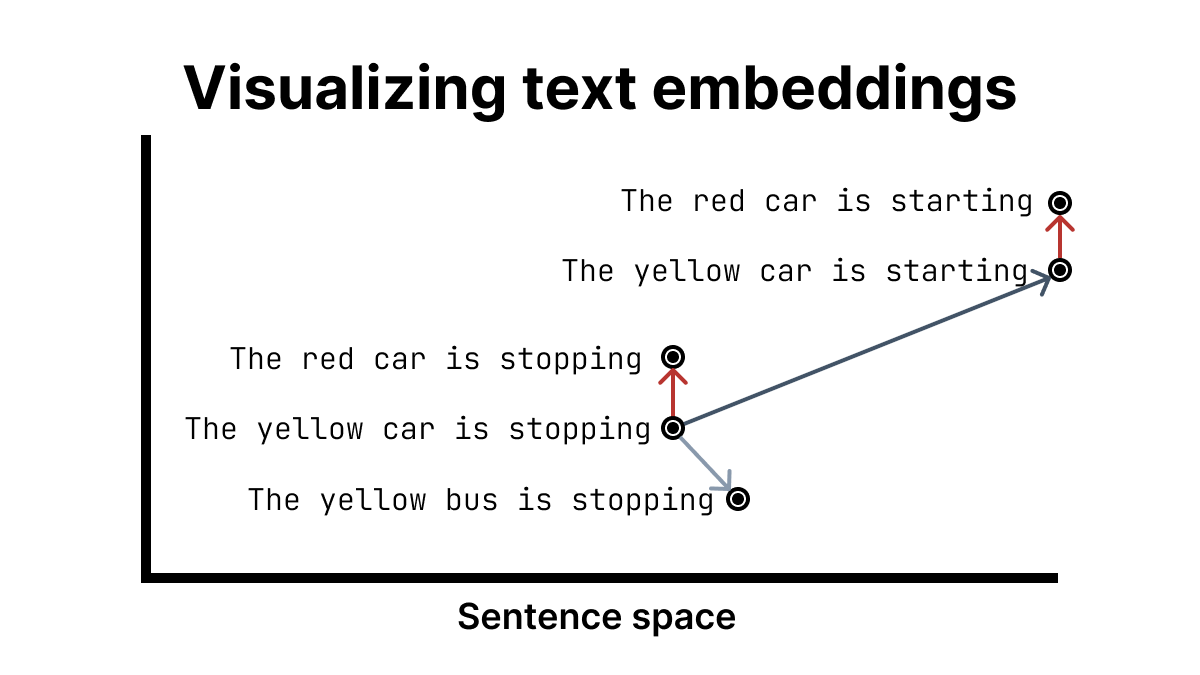
Here, we have a simplified two-dimensional vector space for sentences. The sentences are clustered by similarity, with the same change in a sentence (e.g. yellow -> red) resulting in the same direction and magnitude of shift in sentence location.
Of course, what’s happening in the model is far more complex than this example, but the basic intuition remains the same. Text embedding models encode the meaning of chunks of text into vectors, which can then be compared and grouped.
Along with this general intuition, it’s worth understanding three key aspects of text embedding models: their tokenizer, context window, dimensionality, and similarity function.
Tokenizer
Like large language models, text embedding models use a tokenizer to split up the input text into chunks called “tokens” to be encoded. This happens behind the scenes in the encoding function.
Every embedding model we’ll talk about uses “subword tokenization,” which is also standard for LLMs. This form of tokenization strikes a balance between limiting the number of possible tokens and making each token meaningful.

Subword tokenization gives short, common words their own token, while splitting up larger and more complex words by their roots, prefixes, suffixes, and other components.
Context window
Like LLMs, text embedding models have a context window: the number of tokens of input they can process at once. If you give a text embedding model a string that’s too long, it will only encode the meaning of the first N tokens of the string, where N is the number of tokens in its context window.
A larger context window allows for embedding more substantial pieces of text, which expands the use cases for the text embedding model. A context window of 256 tokens (~200 words) lets you create embeddings of a book a page at a time, while a 8,192-token (~6,000-word) context window will let you process whole chapters at a time.
One trick to using text embedding effectively is finding the right chunk size when embedding a corpus of text. For your use case, do you get the most value from retrieving sentences, paragraphs, or pages? If you need to embed longer chunks of text for the project to work, you’ll be limited to picking text embedding models with larger context windows.
Dimensionality
One cool property of text embedding models is that no matter how short or long the input string is, the output will be exactly the same length.
That’s because a text embedding model has a fixed dimensionality, or length of output sequence. Remember, the output of a text embedding model is a vector, or list of floating-point numbers. Having every output the same length is essential for using embeddings later on.
Similarity function
Every use case for text embedding models involves comparing vectors. Every vector produced by the model will be the same length, and linear algebra gives us three popular comparison methods:
Euclidean distance, which measures the linear distance between the endpoints of two vectors.
Cosine similarity, which measures the angle between two vectors. This is the only similarity function that does not consider magnitude.
Dot product similarity, which is calculated based on each component of two vectors.
While each method has its advantages and disadvantages, what’s most important when building with text embedding models is always using the same similarity function to create consistency between comparisons.
Selecting an open source text embedding model
New and updated open source text embedding models are released every week. You’ll find thousands on Hugging Face. Which model to pick depends on your use case and compute resources.
When building with text embedding models, it’s essential to pick a model that meets all of your needs. If you decide to switch models, you’ll need to regenerate embeddings for your entire database with the new model; you can’t meaningfully compare embeddings generated with different models.
Check out our guide to open-source embedding models for recommendations!
Serving text embedding models with BEI
Many modern text embedding models are now LLM-based. This means LLM-oriented performance optimizations like TensorRT-LLM can accelerate embedding model inference.
We built BEI, the fastest runtime for embedding models in the industry. With BEI, you get lower latency, higher request volume, and up to 2x the token throughput of previous solutions.


Here’s a demonstration of using BEI for inference on Mixedbread Embed Large V1, a high-quality embedding model that runs fast on L4 GPUs.
Creating a Truss
We start by installing the truss package from PyPI and initialing an empty Truss:
pip install --upgrade truss
truss init embedding-modelEnter a model name like Mixedbread Large V1 when prompted.
Configuring BEI
In the Truss’ config.yaml file, we can configure the runtime.
1model_metadata:
2 example_model_input:
3 encoding_format: float
4 input: text string
5 model: model
6model_name: BEI-mixedbread-ai-mxbai-embed-large-v1-embedding-truss-example
7python_version: py39
8resources:
9 accelerator: L4
10 cpu: '1'
11 memory: 10Gi
12 use_gpu: true
13trt_llm:
14 build:
15 base_model: encoder
16 checkpoint_repository:
17 repo: mixedbread-ai/mxbai-embed-large-v1
18 revision: main
19 source: HF
20 max_num_tokens: 16384
21 runtime:
22 webserver_default_route: /v1/embeddingsDeploy text embedding models to Baseten
With the model packaged as a Truss, we can deploy it to Baseten. In your terminal, run:
truss pushEnter your Baseten API key if prompted, and the model will be deployed to your account.
Running inference on text embedding models
Once the model is deployed, we can run inference. Text embedding models served with BEI are compatible with the OpenAI SDK:
1from openai import OpenAI
2import os
3
4client = OpenAI(
5 api_key=os.environ['BASETEN_API_KEY'],
6 base_url="https://model-xxxxxx.api.baseten.co/environments/production/sync/v1"
7)
8
9embedding = client.embeddings.create(
10 input="Baseten Embeddings are fast",
11 model="model"
12)More on text embedding models
If this primer got you excited about text embedding models, there are a ton of resources to explore:
Our writeup on BEI for embedding inference.
Resources from vector store provider Pinecone like intros to embeddings and vector similarity.
For inspiration on projects, check out embeds.ai, a text embedding battleground where you can compare the performance of popular open and closed source text embedding models.
Subscribe to our newsletter
Stay up to date on model performance, GPUs, and more.





