How to serve 10,000 fine-tuned LLMs from a single GPU





TL;DR
You can now swap LoRAs during LLM inference with TensorRT-LLM on Baseten. This means you can serve thousands of fine-tuned variants of an LLM from a single GPU while maintaining a low time to first token (TTFT) and a high tokens per second (TPS).
Let’s say you’re building a product that requires many fine-tuned models, such as a support system with a specialized LLM per customer or a chatbot that’s adjusted to each user’s preferences. It’s infeasible to serve each of these fine-tuned models individually—the cost and model management overhead would be unsustainable.


Instead, you’ll want to serve multiple fine-tuned models at once in a single deployment. If you fine-tuned the models with LoRA (Low-Rank Adaption), you can take advantage of built-in LoRA swapping in TensorRT-LLM to seamlessly serve many fine-tuned models from a single deployment.
LoRA swapping with TensorRT-LLM has a couple of cool properties that make this possible:
LoRA swapping is compatible with in-flight batching. Every request in a batch can use a different LoRA.
LoRA swapping does not meaningfully affect latency. Loading LoRA weights from CPU memory takes 1-2 milliseconds and only happens once per request at the start of generation.
In this article, we’ll review how LoRAs work and discuss how to serve as many as ten thousand LoRAs in production on a single GPU.
What is a LoRA?
LoRA stands for Low-Rank Adaption and is a compute- and space-efficient technique for fine-tuning generative AI models like LLMs. LoRAs are well-suited for small adjustments to a model’s behavior, such as teaching a model to recognize patterns in an internal database or detect abuse and fraud in a specific type of message like customer service chats.
To understand how LoRAs work, we have to review how generative models work in general. To keep things simple, we’ll focus on LLMs. And to radically oversimplify things, we’ll think of LLMs as a really big matrix. (If you want to be really technical about it, they’re actually quite a bit more complex than that — an LLM is several big matrices.)
But for this explanation, we only care about the biggest matrix: the model weights.


How do we get from the original LLM to the fine-tuned LLM? In the LoRA fine-tuning process, we define a delta matrix that alters the original model weights to change the model’s behavior.


The problem here is memory. Expressing a billion parameters of weights in FP16 takes two gigabytes of space. Storing and reading a delta matrix of the same size would make inference much slower and more expensive.
Fortunately, delta matrices defined by LoRA have a low rank. This means that while the matrix itself is very large, it has relatively few “independent variables'' or meaningful dimensions. Most values within the delta matrix are zero. Because of this, we can express the fine-tune using reduced matrices and a tiny fraction of the memory.
A LoRA defines a delta matrix by multiplying two smaller matrices together.
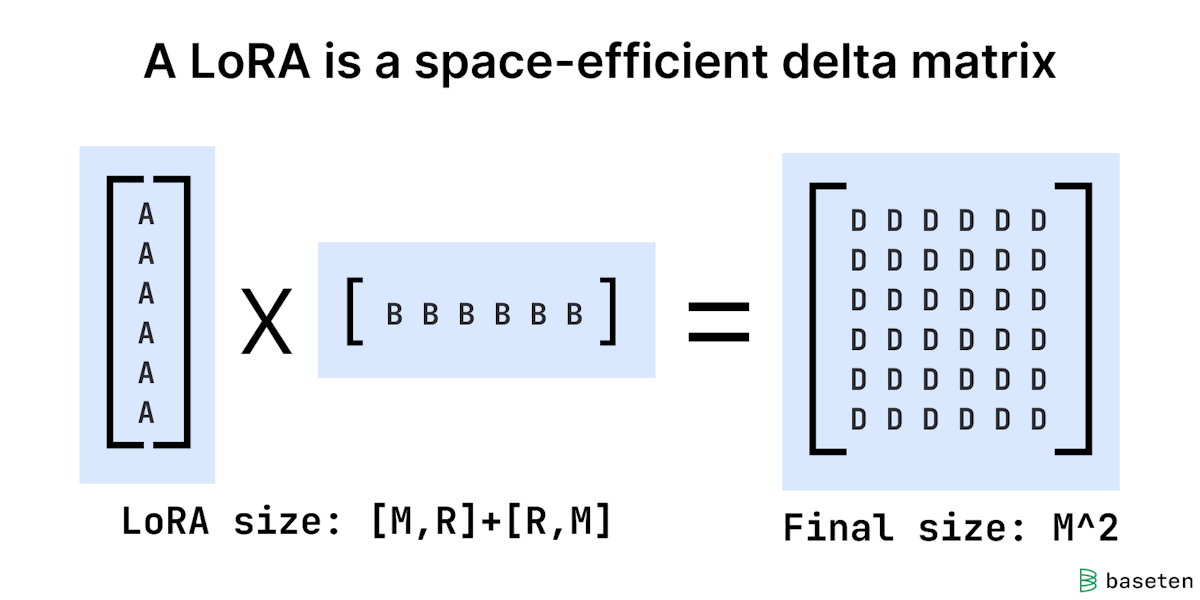
This setup drastically reduces the number of parameters that need to be trained and stored. For a 58-million parameter fine-tuned matrix, a rank-8 LoRA uses 400 times fewer parameters.
original_matrix = 4,096 * 14336 = 58,720,256
rank_8_lora = 4,096 * 8 + 8 * 14336 = 147,456
lora / original_matrix = 0.0025 = 0.25% = 400x fewer parametersThese numbers are arbitrary; actual matrix and LoRA sizes and ratios will vary from model to model. A larger change to model behavior can be created by increasing the rank of the matrices used at the expense of storage. Thus, LoRAs are both an efficient and scalable method for fine-tuning.
What is TensorRT-LLM
TensorRT-LLM is an SDK for inference optimization on NVIDIA GPUs. TensorRT-LLM simplifies the process of creating high-performance TensorRT engines for large language models.
TensorRT works by compiling models to optimized CUDA instructions. While TensorRT engines offer great performance, they’re very inflexible. Each engine is specific to a given GPU, input and output sequence length, batch size, quantization, and of course model. Rather than repeating this process for each fine-tuned model, we can build a single engine that works for the foundation model and swap LoRAs in and out as needed at inference time.
For more details, read our primer on TensorRT-LLM.
Caching LoRAs for inference
Like ordinary model weights, LoRA files need to be stored securely and made quickly accessible during inference. Unlike model weights, LoRAs are generally not bundled into the model serving engine when it is built. Rather, they are cached on system memory at request time, which is possible thanks to their small size.
Where are LoRAs stored?
LoRAs can be stored on:
GPU memory: the LoRA is actively being used on the GPU to fulfill an inference request.
Capacity: 10s/100s of LoRAs
Load time: Instant
Host/CPU memory: the LoRA is cached on system memory within the model serving instance.
Capacity: 1000s of LoRAs
Load time: 1-2 ms
Disk: the LoRA is cached on container storage attached to the model serving instance.
Capacity: Effectively unlimited
Load time: 10-100ms
Network: the LoRA is living in an HF repo, S3 bucket, etc.
Capacity: Effectively unlimited
Load time: ~100ms
Exactly where and how to store LoRAs is up to you. You have access to three levers:
You can configure the amount of GPU memory allocated to LoRA cache.
You can configure the amount of CPU memory allocated to LoRA cache.
You can choose to load LoRAs at startup or at request time.
The implementation we use most often is to download the LoRA at runtime the first time it’s requested and cache it on the host (CPU memory). If you only have a handful of LoRAs, there may be enough room after model weights, activations, and KV cache to store them directly in the GPUs VRAM. But caching LoRAs off the GPU in the host memory allows for each deployment to access far more LoRAs.
How many LoRAs can be stored and used?
On startup, TensorRT-LLM shows the capacity of the device and host LoRA cache, which tells you how many LoRAs will fit. This is useful on a per-deployment basis because it tells you how many LoRAs your particular combination of model and hardware can support.
More generally, there are limits on the number of active and cached LoRAs:
Up to max_batch_size LoRAs can be actively in use at any given time — one LoRA per active request to the model.
Thousands to potentially tens of thousands of LoRAs can be accessible to the system, depending on the size of the LoRAs and where they are stored.
For example, for Llama 3 8B on an H100 GPU, you might have a batch size of 16 concurrent requests, so you can have up to 16 active LoRAs. But how many LoRAs could be cached in that situation?
An H100 has:
80 GB of VRAM
3.5 TB/s of VRAM bandwidth
The attached CPU on a model serving instance has:
Hundreds of thousands of GB of RAM
10 to 50 GB/s PCIe connection
Host memory — the RAM for the CPU attached to the GPU instance — may be too slow for any part of the model itself, such as the KV cache. But LoRAs are so small that they can be stored on the host memory and swapped quickly over the PCIe bus onto GPU memory when needed.
A LoRA for Llama 3 can be as small as 16 megabytes. Even with a low-end 10-gigabyte-per-second PCIe connection, that should take just under 2 milliseconds to load from host memory. H100 instances on Baseten come with 234 GB of system RAM, so they could theoretically hold 14,976 LoRAs, though in reality some RAM is needed for other tasks.
lora_size = 16MB
pcie_speed = 10GB/s
system_ram = 234GB
lora_load_time = lora_size / pcie_speed = 1/640 = 1.56 ms
total_lora_capacity = system_ram / lora_size = 14976Actual capacity will vary depending on LoRA size, instance type, and other workloads’ needs, but we can typically assume that an H100-backed model serving instance can hold ten thousand ordinary LoRAs for 8B-size models.
Accessing LoRAs at runtime
With the LoRA values stored separately, they need to be combined with the model weights at runtime. While we could do this before runtime — multiply the LoRA matrices to get the delta matrix, merge it into the original weights, and run the modified model — that would completely defeat the memory efficiency we’ve gained from storing only LoRA values.
Why should we compute the delta matrix at runtime?
This might be somewhat surprising. Sure, memory is a limited, but so is computation. If we’re going to do a computation multiple times, shouldn’t we cache the results?
Remember that a delta matrix has hundreds of times more parameters than the LoRA matrices. The delta matrix would take almost the same amount of memory as the model weights, so it’s impractical to cache it. And as it turns out, the computations we do to use the LoRA weights at runtime are very inexpensive. At runtime, we:
Run the input tensor through the original model weights.
Fetch the two low-rank matrices that comprise a LoRA.
Multiply input tensor by the first low-rank matrix and then the second low-rank matrix, creating a delta matrix on input tensors.
Add the delta matrix on input tensors to the results of the forward pass through the original model weights.
The key insight here is that once we’re up to two full-size matrices, the delta and original matrices, we add rather than multiply. Matrix addition is a linear time operation, matrix multiplication is approximately O(N^2.37), so worse than quadratic time. We only do expensive multiplication on small matrices, so it’s feasible to run these calculations each time we load a LoRA.
How do we specify which LoRA to use?
LoRA swapping is compatible with in-flight batching on TensorRT-LLM, meaning that each request to our model server can hit a different fine-tuned model.
To specify which fine-tune to use, the request provides a parameter lora_hf_repo which we convert into a three-part format that TensorRT-LLM understands:
task_id, which must be passed each time a given LoRA is called.weights, which is cached after the first request to a given LoRA.config, which is also cached after the first request to a given LoRA.
These parameters are passed to the Triton model server. In the case where the task_id is not found in the cache, we added error handling to fall back and retrieve the fine tune from disk or network.
Serving RS-LoRA and DoRA fine-tunes
LoRA swapping with TensorRT-LLM unlocks flexible inference for fine-tuned models by removing cost, performance loss, and model management overhead as blockers for shipping fine-tuned models to production. As new forms of efficient fine-tuning are developed, the same benefits will need to extend to these new approaches for them to be feasible in production.
Fortunately, the same LoRA-swapping method is compatible with newer variations of LoRA:
RS-LoRA, or rank-stabilized LoRA, is already supported
DoRA, which separates magnitude from direction for even lower rank, is coming soon
TensorRT-LLM receives frequent updates to support new approaches to model optimization, and we work quickly to make these new versions available and production-ready for model serving on Baseten.
Chat with us if you have a set of fine-tuned models and need fast, secure, reliable infrastructure for serving them in production.
Subscribe to our newsletter
Stay up to date on model performance, GPUs, and more.






