Model autoscaling features on Baseten




Autoscaling is the ability of your machine learning model to automatically spawn more replicas or terminate replicas in response to the amount of incoming traffic. Because model traffic is rarely ever consistent, autoscaling helps ensure you’re only paying for the computing resources that you’re using. This post will go through the Baseten model resources and autoscaling features.
Minimum and maximum replicas
On Baseten you can choose both the minimum and maximum number of replicas that your model uses, ensuring that you only pay for the resources that you consume.
So if you’ve selected eight maximum replicas, but your model is only receiving an amount of traffic that requires one replica, you’ll only be charged for the use of one replica. In other words, you can think of the maximum number of replicas as a spending cap–you’re setting the upper limit on the number of replicas you’d like your model to utilize in response to increased traffic.

Because of how our infrastructure is configured, you don’t need to worry about losing traffic if your maximum number of replicas is set too low and you suddenly have a big burst in traffic. All excess traffic is placed in a queue, and processed either as the load in traffic decreases, or you increase the maximum number of replicas.
We love a good autoscaling challenge! Learn more about how we served four million Riffusion requests in two days.
Scale to zero
By default, when you deploy a new model, the minimum number of replicas is set to zero and the maximum is set to one. When your minimum number of replicas is set to zero, scale to zero is enabled, which means your model will be put to sleep after a period of inactivity. You can turn scale to zero off by setting your minimum number of replicas to one or higher, but be aware that by doing so your model will always be consuming some compute, even if it’s not receiving any requests.
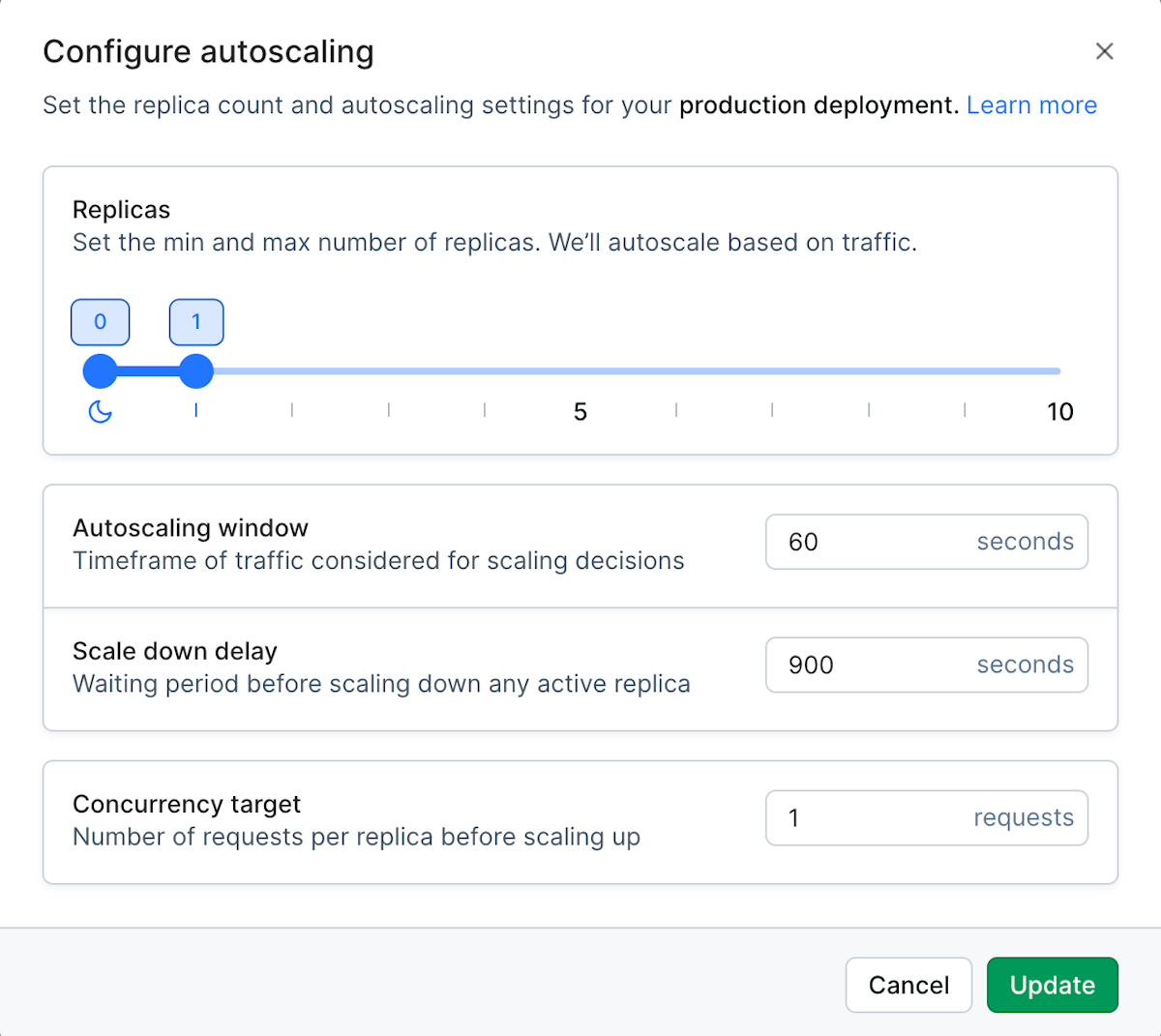
Model autoscaling settings
In addition to setting the minimum and maximum number of replicas for your model, you have three additional controls for how your published model is run: autoscaling window, scale down delay, and concurrency target.
Autoscaling window
The autoscaling window is the timeframe used for analyzing incoming traffic. This helps ensure that the autoscaler doesn’t overreact to small changes in traffic, and waits the specified time to see if the changes are stable.
Default: 60 seconds
Minimum: 10 seconds
Maximum: 3600 seconds (1 hour)
Scale down delay
Additional scale down delay refers to an additional amount of time that must pass before scaling down a replica, once the aforementioned scaling delay has been accounted for. Because scaling up is more time consuming, it often helps to make sure the reduced traffic has gone away by adding some more time to the scaling decision window. This helps maintain replica capacity when request traffic fluctuates.
Default: 900 seconds (15 minutes)
Minimum: 0 seconds
Maximum: 3600 seconds (1 hour)
Concurrency target
Concurrency target refers to the number of requests that are allowed to be made on one replica at any one time. If the value you’ve selected is exceeded, additional replicas will be scaled up to accommodate the requests.
Putting it all together
To demonstrate how all of the Baseten autoscaling features work in concert with one another, we ran a load test where we sent a series of sequential requests to our model, and have shared the graphs below. We set the autoscaling window to one minute so that our model would quickly scale down, allowing us to show off all of our autoscaling features in action.




Baseten model cold starts are incredibly fast
Cold starts
Cold starts, which refers to bringing a model up from zero to (at least) one replica after the model has been scaled to zero, are enabled on all Baseten accounts. Going from this zero to one state is particularly difficult in the machine learning world because of the sheer size of the thing that we’re trying to scale–if you’re working with large open source models, the model weights are massive. And because GPU compute is expensive, we don’t want idle compute laying around. Once our model scales to zero and is no longer using computing resources, it’s important for it to respond quickly to any new traffic with minimal delays.
To get an idea of just how fast our cold starts are, for Stable Diffusion XL on an A100, we reliably see cold start times of 9 seconds, from zero to ready for inference.
Bring your model — we'll handle the rest
We’ve covered the autoscaling features available to you on Baseten. Now it’s time to start building! Take any of the models from the Baseten Model Library, or package your own model using Truss, our open source model packaging and deployment framework, and deploy it to Baseten. From there you can invoke your model through either the Baseten client or curl. And be sure to tag us on Twitter–we’d love to see what you build!
If you have any questions or run into issues while working with Baseten, please reach out to us at support@baseten.co.
A special thank you to my colleagues Amir, Jo, Matt, and Phil for taking the time to share their infrastructure expertise with me!
Subscribe to our newsletter
Stay up to date on model performance, GPUs, and more.











