Understanding performance benchmarks for LLM inference




TL;DR
Model performance benchmarking is tricky because there isn’t one universal, objective number to optimize for. Instead, better inference performance is about tradeoffs that make sense for specific use cases.
Large language models (LLMs) require nuanced performance benchmarks. But they aren’t the only systems that are hard to boil down to just one number.
Take cars for example. What makes a car fast? Some people measure acceleration, others measure top speed. And there are dozens of other metrics that matter for real-world use, from miles per gallon to towing capacity.
Naturally, manufacturers like to advertise benchmarks that show their cars at their best. Electric cars excel at 0-60 acceleration, while gas-powered sports cars tend to win longer quarter-mile races. Similarly, inference providers want to focus on benchmarks where they do well.
This guide will help you understand performance benchmarking for LLMs. You’ll learn how to select metrics for your use case and what factors to keep in mind when comparing models and inference providers.
Selecting benchmark methodology
When testing a racecar on a track, hundreds of factors matter, from what tires you use to what direction the wind is blowing. There are also many variables to consider when benchmarking large language models.
Important factors when benchmarking large language models:
Hardware: What GPU is the model running on? Higher-performance hardware generally costs more to run.
Streaming: Is the model sending output a token at a time, or only responding when the full output is ready?
Quantizing: Is the model running at full precision, or is it quantized? Learn more in our guide to quantizing.
Configuration options in the benchmark itself to set:
Input size: How many tokens is the LLM receiving as input? More input means it takes longer to start a response.
Output size: How many tokens is the LLM producing as output?
Batch size: How many requests is the LLM processing concurrently? A larger batch size generally means worse latency but better throughput.
Questions of how to present the benchmarks:
Percentile: Are the benchmarks best-case, average, or worst-case results? This is often expressed as a percentile (e.g. p90 means that 90% of requests meet or exceed the value).
Network speed: What connection does the end user have to the LLM? For end-to-end benchmarks, network speed can alter results.
These factors need to be accounted for when comparing benchmarks between models or inference providers.
Measuring latency
Latency for LLMs is roughly analogous to a car’s acceleration — how quickly can you get up and running?
A user’s impression of how fast a service is mostly comes down to latency. The best way to make LLMs feel fast for chat-type use cases is to stream the model output — delivering the model output as it is generated rather than once it is completely done.
Time to first token
When streaming model output, the key latency number is time to first token: how long does it take from when the user sends a request to when they receive the first characters of model output?
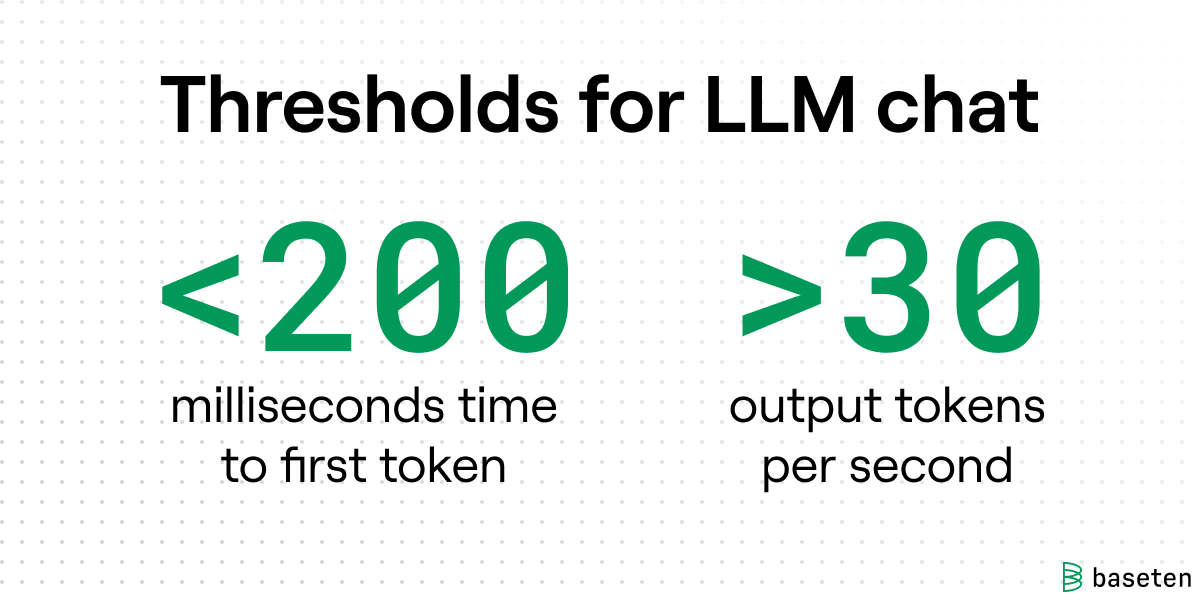
Human visual reaction time averages around 200 milliseconds, so getting your time to first token below this threshold makes chat-type applications feel snappy and responsive. Time to first token can depend on factors like network speed, input sequence length, and model size, so it’s a benchmark to be particularly careful when measuring.

Total generation time
Total generation time is the end-to-end latency from when an LLM is called to when the output is finished. It will depend on the length of the output and the speed at which the model can create text.
Streaming improves time to first token by 10-100x or even more, but it does make the total generation time very slightly longer. If your use case doesn’t call for streaming, turn it off to get a better benchmark for total generation time.
Cold starts
When a model is scaled to zero and gets called, there’s a cold start time as the model server spins up to handle the request. A slow cold start destroys latency. Baseten has done a lot of work to make our cold starts fast, but when running latency benchmarks it’s critical to specify whether or not the latency measured includes a cold start time.
Measuring throughput
An LLM’s throughput is how many requests it can process in a given period of time or how much output it can produce. If latency is a car’s acceleration, throughput is more like its top speed.
Sometimes, you’ll face tradeoffs between throughput and latency, but the two aren’t always opposed. For example, upgrading to a more powerful GPU or more efficient serving engine can improve both throughput and latency.
On the other hand, batching or concurrency — running multiple requests through the model at the same time — tends to make throughput better but latency worse.
Requests per second
Requests per second is a standard measure of throughput for API endpoints outside of the AI/ML world.
For LLMs, requests per second depend on total generation time and concurrency. However, total generation time varies based on how long the model’s input and output are.
More often, we use an LLM-specific metric, tokens per second, for measuring model throughput.
Tokens per second
There are multiple different measurements of tokens per second:
Generally, total tokens per second is used as more of an absolute measure of throughput, while output tokens per second is more relevant when benchmarking for real-time applications like chat. Perceived tokens per second shows what the user experiences once they start receiving a response.
Combined with a fast time to first token, a high output tokens per second is essential for real-time applications like chat.
Sources differ on average reading speed, but it’s probably between 200 and 300 words per minute, with the very fastest readers approaching 1,000 words per minute.
For most LLMs, 4 tokens approximately equals 3 words. At 30 tokens per second, you’re generating as many as 1,350 words per minute — more than enough to stay ahead of the fastest readers, even after accounting for punctuation.
Of course, a higher tokens per second is always better. It’s just a question of diminishing marginal returns. Though a few extra tokens per second may be needed for generating structured text like code or markdown, 30 output tokens per second is a good minimum threshold for chat applications. Other use cases may require substantially higher output.
With a fast time to first token, output tokens per second and perceived tokens per second are similar. The two measurements differ for tasks with very long input sequences or very short outputs, such as summarization.
Measuring cost
If raw performance were all that mattered, every LLM would run on top-of-the-line GPUs. And, while we’re at it, we’d all drive Bugattis. But cost matters just as much as performance.
Hardware choice — specifically GPU — is usually the biggest factor in cost. Generally, you want to use the least expensive hardware that is capable of meeting your performance requirements.
But there isn’t often a ton of flexibility around GPU choice. Many models require larger, more expensive GPUs for inference. In these cases, we can look into hardware utilization.
As LLM inference tends to be memory bound, batching isn’t just a way of increasing throughput, it’s also a way of decreasing cost per token. Depending on the latency benchmarks you’re trying to hit, batching can be a great way to bring cost down to target.
Measuring cost per minute
Baseten bills on a per-minute basis with autoscaling replicas to make sure you only pay for what you use. Under this model, cost depends on the instance type selected — using a higher-performing GPU costs more per minute — but makes cost predictable once you’ve locked in your performance requirements.
Calculating cost per thousand tokens
When benchmarking against API endpoints that charge per token, you have to translate price per minute for a clearer comparison.
minutes_to_generate_thousand_tokens * cost_per_minute = cost_per_thousand_tokensSo if it takes 30 seconds to generate a thousand tokens on a GPU that costs two cents per minute, the cost per thousand tokens is one cent. Increasing throughput decreases the cost per thousand tokens.
Creating quality LLM performance benchmarks
Performance benchmarking for LLM inference is tough. Model performance depends on everything from hardware and quantizing to token count and concurrency.
“My model does 100 tokens/second” is a bad benchmark.
“On an A10G, my model streams at 100 perceived tokens/second with a 200 ms time to first token, assuming a 256-token input sequence, 512 tokens of output, and only one concurrent request” is a good benchmark.
Taking the time to create nuanced benchmarks that reflect your actual needs is essential because it shows where optimization is needed across latency, throughput, and cost.
Subscribe to our newsletter
Stay up to date on model performance, GPUs, and more.







