Updated defaults and language for autoscaling settings

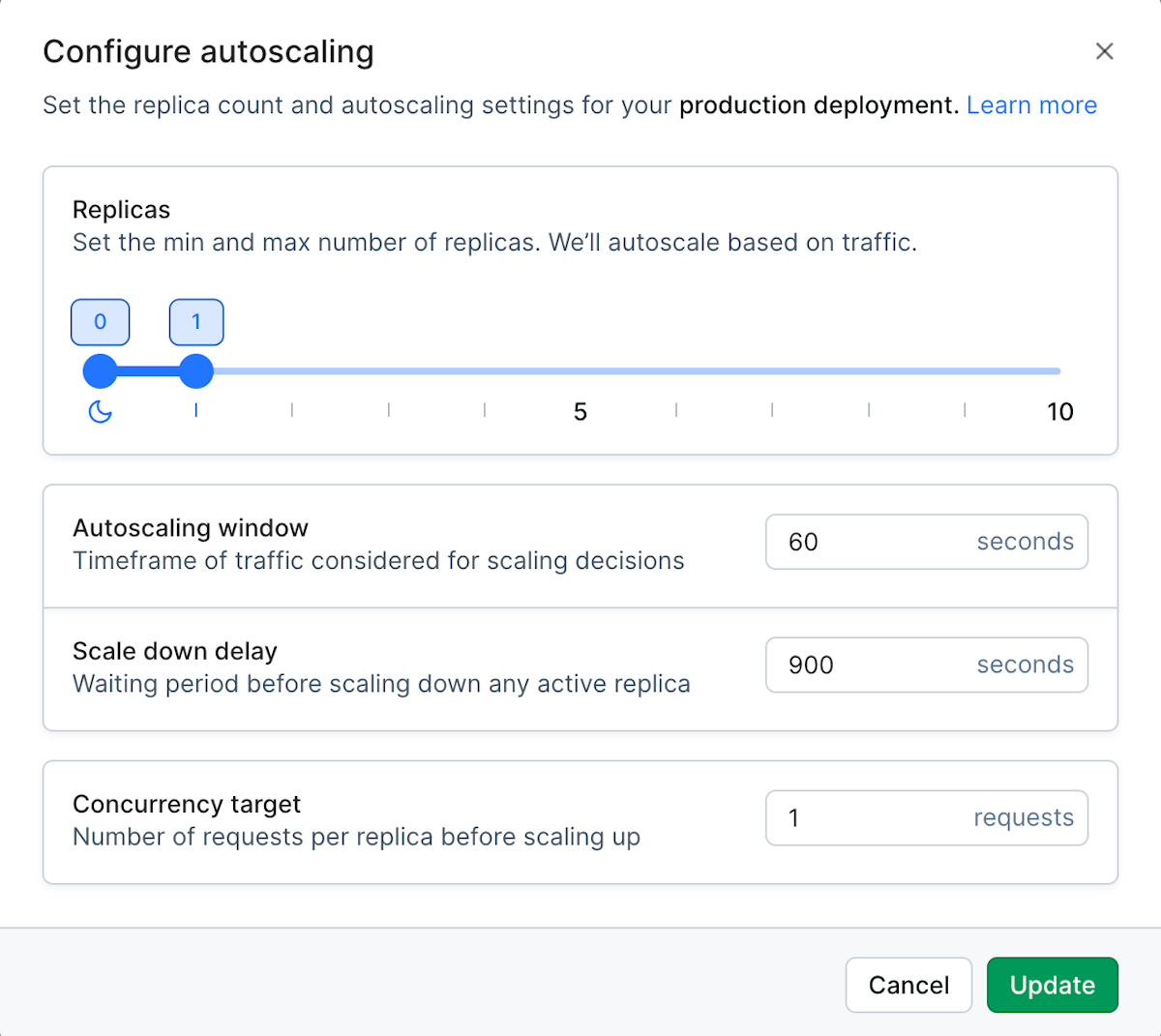
Autoscaling lets your deployed models handle variable traffic while making efficient use of model resources. We’ve updated some language and default settings to make using autoscaling more intuitive. The updated default values only apply to newly created model deployments.
New autoscaler setting language
We renamed two of the autoscaler’s three settings to better reflect their purpose:
Autoscaling window, previously called autoscaling delay, is the timeframe of traffic considered for scaling replicas up and down.
Scale down delay, previously called additional scale down delay, is the additional time the autoscaler waits before spinning down a replica.
Concurrency target, which is unchanged, is the number of concurrent requests you want each replica to be responsible for handling.
New default values
We also assigned new default values for autoscaling window and scale down delay. These values will only apply to new model deployments.
The default value for the autoscaling window is now 60 seconds, where previously it was 1200 seconds (20 minutes).
The default value for the scale down delay is now 900 seconds (15 minutes), where previously it was 0 seconds.
The default value for concurrency target is unchanged at 1 request.
We made this change because, while autoscaler settings aren't universal, we generally recommend a shorter autoscaling window with a longer scale down delay to respond quickly to traffic spikes while maintaining capacity through variable traffic.
Additionally, the scale down delay setting is now available for all deployments, where previously it was limited to deployments with a max replica count of two or greater.
For more on autoscaler settings, see our guide to autoscaling in the Baseten docs.

